Blockchains - demystifying the hype a little

There’s a lot of hype and confusion surrounding blockchain. This article is my attempt to cut the crap a little, primarily for myself.
Most explanations are implementation-oriented (“it’s a chain of blocks” etc). I’ll take a product-oriented expository approach instead.
Three parts:
Preamble
What is blockchain, really?
What is blockchain good for?
Preamble
Story time, courtesy of Gideon Greenspan plus some tweaks.
Suppose a group of participants (companies, individuals etc) wants to set up a financial system, within which they transact/exchange scarce assets. To have/maintain value in this system, scarce assets must stay scarce, which means preventing
Double spending: can’t send the same unit of an asset to more than one place
Forgery: can’t create new units of an asset on a whim
The historical solution was to define asset ownership in terms of owning physical tokens e.g. paper money, coins etc: can’t double spend (laws of physics don’t let you have the same token in two locations) and hard to forge (by making them hard to manufacture).
But there are many problems with physical tokens:
Can be stolen with no recourse/trace
Slow and costly to move in large numbers/long distances
Hard and costly to create hard-to-forge tokens
The (again historical) solution was to redefine asset ownership in terms of a ledger managed by a trusted intermediary, who enacts a transfer of ownership by authenticating requests and then modifying the ledger’s content. This lets questionable transactions be rolled back quickly and easily.
But the problem with ledgers is that control is concentrated in the hands of the trusted intermediary. This creates a huge security issue for maintaining ledger integrity:
External actors can hack into the ledger to steal funds
Internal actors can corrupt the ledger: this attack is hard to detect or prove
Maintaining ledger integrity in the face of this security issue takes a lot of time and money, and entails stuff like requiring ongoing verification between the central ledger and each transacting party’s ledger using batch-based reconciliation.
The solution is to decentralize control over who can modify ledger content by removing the trusted intermediary. Instead, all participants maintain a copy of the ledger with full control over their own assets, and consensus between ledger copies (i.e. reconciliation) is maintained automatically in near-real time by some overarching mechanism (via software). Transactions are sent between participants (i.e. peer-to-peer). Now external actors can’t steal funds, because that breaks consensus; insiders can’t corrupt the ledger because same. This removes hassle and saves cost, improving the efficiency of maintaining ledger integrity.
A natural name for this solution is “shared ledger”. It’s called “blockchain”, however, because that’s the only way people have figured out how to implement this solution, starting with Satoshi Nakamoto (whoever they are) for bitcoin — as a chain of blocks of validated transactions linked and timestamped using cryptography. (Don’t worry if this doesn’t make sense yet. It shouldn’t.)

This solution entails going digital instead of physical. But data in digital ledgers is just zeros and ones, so it’s infinitely copyable, meaning participants can double-spend and forge to their heart’s content, killing asset scarcity and hence value in this financial system. Part of Nakamoto’s innovation was figuring out how to timestamp transactions using cryptography (i.e. automatically), instead of relying on a trusted intermediary, in a way that makes it infeasible to double-spend/forge bitcoins. (I’ll explain how below.)
What is blockchain, really?
A blockchain is a distributed ledger (really a specific kind of distributed ledger): a list of transactions replicated across many computers, instead of being stored on a central server, where
every single user can read everything
no single user controls who can write what
To quote Greenspan, this means that a blockchain is a specific solution to the problem of storing shared transaction data in a low-trust environment that trades off confidentiality for disintermediation. (We’ll elaborate on this confidentiality/disintermediation tradeoff later, because it’s key to understanding what use cases blockchain genuinely adds value to.)
People use the term “blockchain” to mean different things, which is confusing (including for them). But there are common themes: a blockchain is a data store that
usually contains financial transactions (but not necessarily — anything best served by a ledger works, see below for elaboration)
is replicated in near-real time across many systems (to achieve consensus)
usually exists over a peer-to-peer (P2P) network
uses digital signatures and cryptography to prove identity and authenticity, as well as enforcing read/write access rights
can be written by some participants
can be read by some participants (maybe a wider audience)
has mechanisms to make it easy to detect when someone tries to change historical records (“immutability”)
In practice, a blockchain is a normal database plus some software. This software
adds new transactions
validates that these transactions conform to pre-agreed rules
listens and broadcasts new transactions to peers across a network
makes it easy to tell if old transactions are modified or deleted
How are blockchain and Bitcoin related?
Bitcoin uses blockchain technology to prevent double-spending digital currency without relying on a trusted intermediary.
But why a chain of blocks?
To implement immutability.
To clarify: immutability isn’t about making data “impossible to tamper with” (you can’t actually do that), it’s just about making it easy for blockchain participants to tell when it has been tampered with. Conversely, malicious actors can’t easily alter data undetected. This is done by
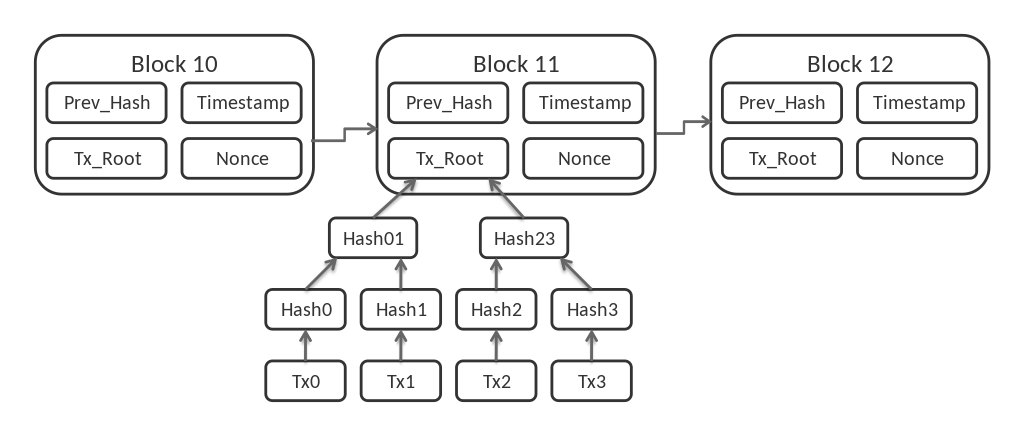
batching transactions into blocks
making it so tampering with a block’s contents alters all subsequent blocks
That 2nd point is Satoshi Nakamoto’s innovation. It’s achieved by having each block contain a cryptographic hash of the previous block’s content. I’ll run through bitcoin’s blockchain for an example implementation of this 2nd point; other blockchains may do it differently.
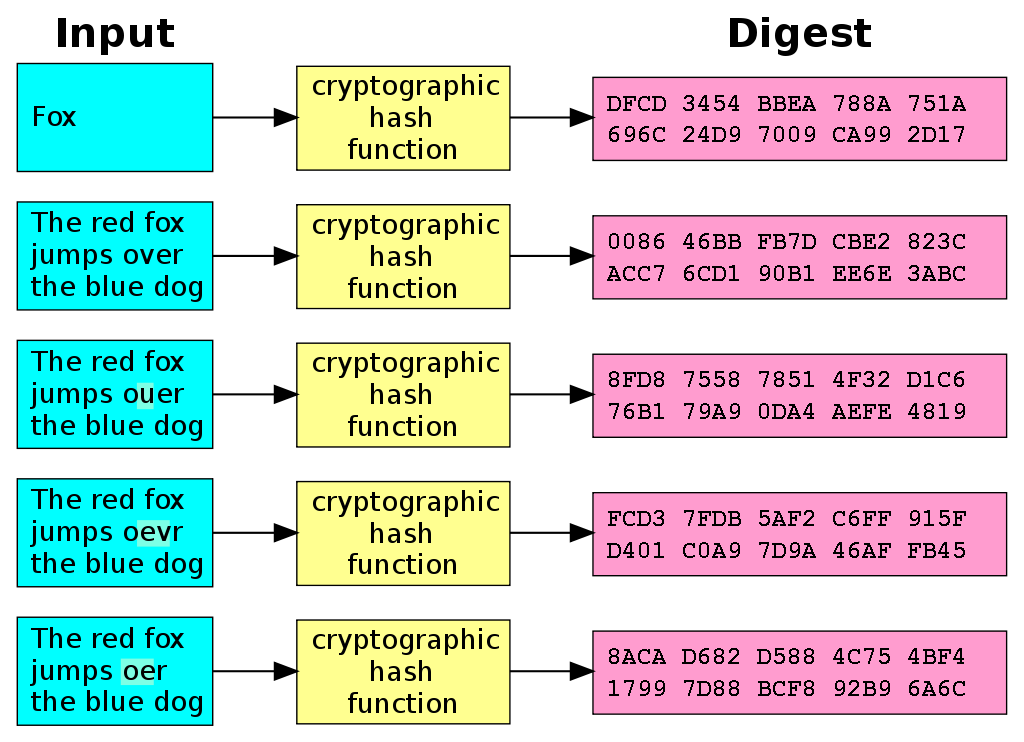
A cryptographic hash is a one-way function: easy to compute, practically impossible to invert. A good hash has an avalanche effect — changing so much as one character in a block’s contents changes the hash output so much it looks completely different:

Now, each block in a blockchain contains a hash that’s a combination of two things:
the previous block’s contents
a number called the nonce, short for “number only used once”
Hashing (block contents + nonce) gives a number, or “hash”. Think of the nonce as an adjustable parameter: different nonces give different hashes. (Different block contents also give different hashes — this will matter below.) The goal is to find the nonce that makes the hash lower than a number called the target.
Because the hash function is one-way, you can’t just start from the target and invert the function to get the nonce. Because the hash function has an avalanche effect, you can’t assume that if a nonce gets you very close to the target, adjusting the nonce just a little more will “get you over the finish line”. This means you have no choice but to try all possible nonces brute-force. This is precisely what proof-of-work is.
So how does all this help implement immutability, i.e. prevent malicious actors from easily altering historical data undetected?
Suppose you alter a block’s data (say, to add a million bitcoins to your account balance). Then hashing (new block contents + original nonce) gives a new hash, one that’s no longer below the target (because avalanche effect), so everyone can tell you changed something. Finding a new nonce to get below target requires the proof-of-work of brute-forcing all possible nonces again, which isn’t easy/cheap.
(In case you’re interested in the math, Satoshi Nakamoto runs through a simple scenario in Section 11: Calculations of his whitepaper.)
Again, this is how bitcoin’s blockchain implements immutability; other blockchains may do it differently.
But why so complicated?
Not necessarily.
Antony Lewis notes that you don’t need the common themes above all at once — instead, it’s useful to think of blockchain as a collection of technologies that you can “remix subsets of” to get different results depending on your use case:

{kind=link}
{kind=link}
{kind=link}
For instance, the reason bitcoin’s blockchain is complicated is its ideology: Satoshi Nakamoto wanted anyone to be able to write to its blockchain, without prior vetting nor approval. (This makes it a “permissionless” or “public” blockchain, with pseudonymous participants.) This means it needs mechanisms to
arbitrate discrepancies (bitcoin’s solution: the longest chain rule)
defend against attacks/misbehavior (bitcoin’s solution: proof-of-work)
All of these mechanisms add to the bitcoin blockchain’s complexity and running cost. But if you’re an industry group running a private blockchain (i.e. a “permissioned” blockchain, with identified participants), you don’t need those complex costly mechanisms to arbitrate discrepancies and punish misbehavior, because not just anyone can write to your blockchain anymore. Just use legal contracts instead: “behave or we’ll take you to court”.
Here are some other ways to remix the bag of blockchain technologies, again to emphasize that bitcoin’s blockchain is just one of many different possible kinds depending on use case:

{kind=link}
Why distributed?
Because the whole idea is to enable interaction between multiple peers without relying on a trusted intermediary.
I’ll add a few words on the centralized vs distributed approach to storing data. Naively, it doesn’t matter to the user how you store data, so the simplest approach would just entail storing everything in one place. This is called a centralized architecture.
But there are risks to this approach:
Scalability + speed (both storage and access traffic bandwidth)
Resilience (single point of failure puts all data at risk)
Both problems can be solved by connecting multiple databases (nodes) to each other via computer network, letting data stored in each physical location be manageable independently of other locations, and replicating data across databases. This is called a distributed architecture.
The distributed approach trades scalability + speed + resilience for complexity, which leads to some downsides:
Harder to manage, modify, backup
Harder to present unified view to users
Higher cost
Then isn’t blockchain just a distributed database?
No, it’s a subset.
The key distinction is trust: a distributed ledger like blockchain is a solution to the problem of storing data for parties who don’t fully trust each other, unlike a distributed database.
Users of a distributed ledger have a reason to cheat each other, because a ledger stores data pertaining to balances and is linked to accounts
Users of a distributed database don’t usually have a reason to cheat each other, because databases can in theory hold any kind of data
This makes distributed ledgers decentralized databases. They’re about shared control, not shared data.
Let’s back up a bit.
Decentralized systems are not the same as distributed systems — the former is a subset of the latter. The key distinction is in how system-wide decisions are made.
Distributed systems share information and resources (e.g. processing)
Decentralized systems also share decision-making control

{kind=link}
A related distinction (for an intuition pump, think “communism vs capitalism”):
Distributed systems with centralized control use complete system knowledge to make decisions
Nodes in decentralized systems typically don’t have complete system knowledge, and don’t need to; system-wide behavior “emerges” out of collective decision-making
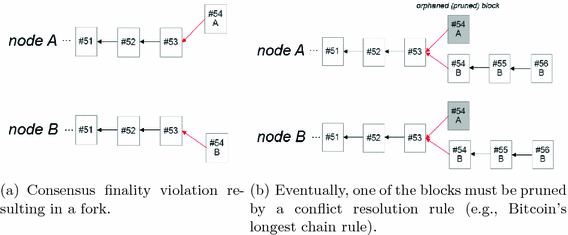
This “emergent decision-making” is how, for instance, bitcoin’s blockchain arbitrates discrepancies between different “forks” comprising validated transactions, via the longest chain rule. (Technical aside: bitcoin doesn’t use “number of participants” to validate transactions, because attackers can easily create fake sockpuppet identities to win the numbers game; this is called a Sybil attack. Instead it makes it costly to validate transactions — precisely what proof-of-work achieves. Bitcoins are awarded to incentivize this costly validation.)

{kind=link}
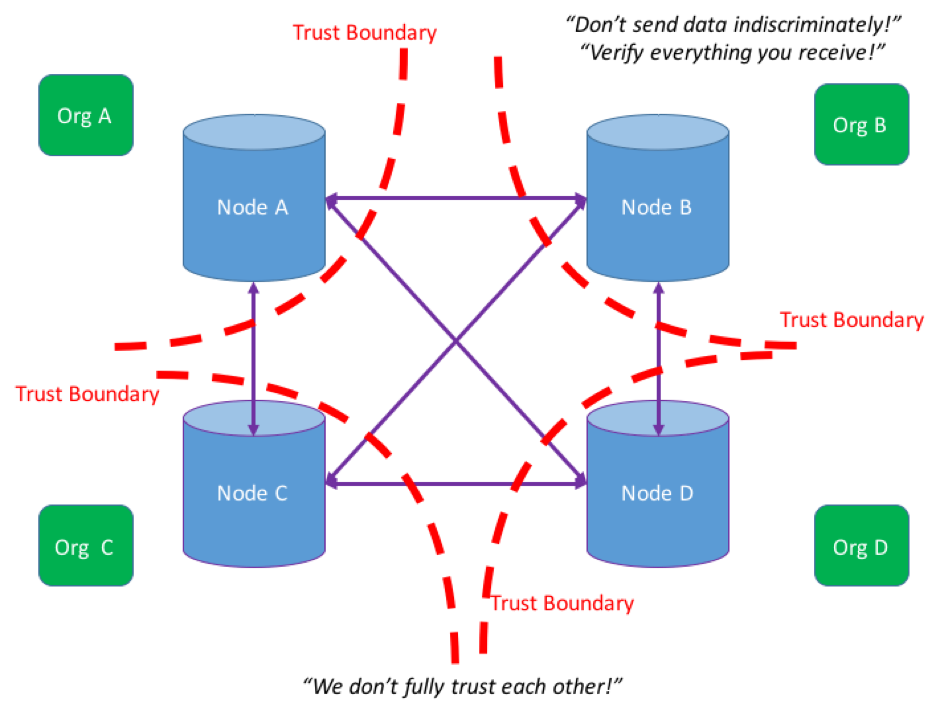
Now we can start to understand why distributed ledgers have to be decentralized databases. In a distributed database, a group of nodes (computers, companies, etc.) under a single organization’s control cooperate to maintain their state (either by partitioning the overall dataset or maintaining replicas) to present a unified view to users. Nodes trust each other and distrust the wider world outside the system:

{kind=link}
This is fine for storing most data, including finance sometimes.
But not always. Sometimes you need to maintain your own records for shared data because you can’t trust peers to not cheat you: maybe they’ll send fake data, and maybe they’ll publicize the data you sent them. (Richard Brown argues that a huge amount of cost and inefficiency in financial markets stems from suboptimal solutions to this problem.) This is when you need distributed ledgers, to decentralize control. It involves redrawing the “trust boundary”, but still presents a unified view to users:

{kind=link}
Then isn’t blockchain just a distributed ledger?
No, it’s a subset.
The key distinction is confidentiality: how much participants share, and who they share what with. Blockchain-as-we-know-it lets all participants see all transactions, so no confidentiality (forget anonymity — that’s why I wrote “pseudonymous vs identified” blockchains above instead of “anon vs ID”; this is how the FBI busted Silk Road criminals). Like I wrote above, blockchains trade confidentiality for disintermediation.
But there are use cases where you want more confidentiality than that, like in a lot of “core banking” operations like loans, mortgages, deposits, and payments, as well as bilateral stuff like capital markets business. The solution is twofold:
Data segregation: limit who can read/write transactions into channels containing “sub-ledgers”
Channel independence: only require consensus on a sub-ledger’s state to parties within a channel
While this model bears a familial resemblance to blockchain, it’s different enough that it’s worth calling it by its own name. Colin Platt calls it a “distributed multichannel ledger”:
We’ll make this point more clearly below when we talk about distributed ledger technologies (DLTs), but here’s a quick summary by Antony Lewis:

{kind=link}
Why so narrow? Is blockchain just a solution looking for a problem?
No.
Satoshi Nakamoto invented bitcoin’s blockchain to solve a well-defined problem:

{kind=link}
Bitcoin, of course, uses (a specific kind of) blockchain. Of course that’s not the only problem it solves…
What is blockchain good for?
Cynically: to garner interest, funding, customers and drive up company valuation. This started happening in ~2015. It’s characterized by this sort of talk:
“We’re a blockchain-powered company”
“We send it over blockchain”
Saying that “blockchain” is the solution to all kinds of use cases without specifying which kind of blockchain for which use case
Especially egregious are bitcoin companies who rebranded themselves as blockchain companies to avoid bitcoin’s negative connotations and avoid regulatory scrutiny. I won’t name names.
More usefully:
Blockchain, remember, is a solution to the problem of storing shared transaction data in a low-trust environment where it makes sense to trade off confidentiality for disintermediation. This suggests the following use cases (h/t Greenspan, Lewis):
Lightweight financial systems: crowdfunding, gift cards, loyalty points, local currencies; P2P trading between asset managers not in direct competition; internal department-specific accounting systems in large organizations. “Lightweight” here means the number of participants is relatively low, as are the economic stakes, which is why confidentiality loss is not a big issue, and the hassle and cost of setting up a trusted intermediary is not worth it
Provenance tracking in supply chains: tracking origin and movement of high-value items e.g. luxury goods, electronics, pharmaceuticals; also critical documentation e.g. letters of credit and bills of lading. Blockchain helps like this: when the item is created, a corresponding token is issued to authenticate its point of origin; it moves in parallel with the item as the latter goes through its chain of custody; the final recipient gets both item and token and can look at the latter to verify chain of custody back to point of origin. (For documentation we can dispense with the physical item altogether: just directly exchange tokens in a two-way swap.) The reason blockchain is preferable to centralized database is disintermediation: records comprising chain of custody can be corrupted in the latter so forged/stolen items are marked as legit, which blockchain’s consensus mechanism prevents. The reason confidentiality isn’t a big issue is that (unlike most financial assets) most tokens move in one direction from origin to endpoint, so participants who rarely transact with each other won’t connect blockchain addresses to real-world identities
Inter-organizational record keeping: collectively recording and notarizing any type of data (not necessarily financial), e.g. audit trail of critical communications between organizations in healthcare/legal sectors. Blockchain is preferable to centralized database because of disintermediation: no org in the group can be trusted with maintaining the archive of records, but everyone must agree on its contents to prevent disputes, so confidentiality isn’t an issue. (Note that it’s possible for everyone to agree on content without actually revealing said content, by hashing it — easy to verify, infeasible to invert/“hack”)
Multi-party aggregation of AML/KYC data: similar scenario as above, different motivation: overcoming infrastructure hurdle of combining info from many separate sources. Banks with internal databases of KYC data may share lots of customers, so it makes sense to enter a reciprocal sharing agreement where data is exchanged to avoid duplicated work. Traditionally, two options: (1) Master-slave data replication — banks maintain live read-only copies of others’ DBs and run queries against its own DB and replicas to check duplicates. The issue is that the number of instances grows as the square of participant count, so for 100 banks there’s 10,000 DB instances (1 master & 99 read-only replicas of everyone else’s per bank), which grows unwieldy fast. (2) Trusted intermediary aggregates all data in one big master DB. Blockchain is preferable because (again) disintermediation, plus confidentiality isn’t an issue
Multilateral B2B workflows where participants’ data should match: applies not just to financial services but all industries where it’s critical that data under an org’s control matches data under another’s, i.e. reconciliation during data processing, not after recording. This greatly reduces operational risk. It’s done by building validation criteria and business logic-as-shared-code into the blockchain

{kind=link}
How do I tell if a use case merits blockchain?
There are a few questions to ask:
Why not use a traditional relational database (e.g. SQL Server, Oracle, Postgres)?
Are there multiple participants who can write transaction data?
Is there mistrust between participant writers? (i.e. one user won’t just let another modify its own entries)
Is there anything wrong with having a trusted intermediary as transaction gatekeeper? (Good reasons: lower cost, faster transactions, automatic reconciliation, no intermediary possible)
Do transactions interact? (e.g. X pays Y who pays Z; verifying Y’s transaction depends on checking X’s, so they naturally belong in a single shared ledger)
Are there rules restricting transaction legitimacy? (necessary in low-trust environment; different from constraints in traditional DBs which are related to state, because they’re transformation legitimacy rules)
Who are the transaction validators, and why are they trustworthy? (validators, while less powerful than trusted intermediaries of centralized DBs, can still censor transactions or resolve conflicts biasedly)
For asset ledgers: who stands behind the assets represented on the blockchain?
In particular, if the use case fails any of the first 5 questions, the following options are better, because they are some of the most thoroughly tested and debugged code on the planet:
centralized database
master-slave database replication
multiple databases users can subscribe to (publish-subscribe pattern)