

OpenAI's GPT-3 - what you should know

GPT-3 in short
OpenAI’s GPT-3 is “autocomplete on steroids”: a language model that uses deep learning to produce text by predicting the next word in a sentence, given a prompt.
It’s trained using gargantuan amounts of compute on a diverse corpus of text comprising hundreds of billions of words crawled from the internet, using two major recent innovations in machine learning: attention and unsupervised training.
As the largest language model ever, it generates such high-quality text that in many cases it’s hard to distinguish from human-written text, which suggests myriad applications like automating tasks and augmenting creative content production, but also manifold risks from fake news at scale to social engineering.
Surprisingly, it also “learns to learn”, demonstrating an ability to learn new tasks like translation and arithmetic given a few examples, despite not being explicitly designed for them; “learning to learn” is absent in smaller language models, showing that “more is different” and suggesting implications for artificial general intelligence (AGI) research.
It still can’t do a lot of things however, from reasoning physically about the world to preventing bias in its output text, and the fact that it memorizes everything online during training raises copyright issues for businesses looking to apply it.
OpenAI is currently restricting access to GPT-3 due to the risks above by offering it as a cloud-based API for which users can sign up on a waitlist, thereby controlling usage and letting them roll back access if needed, while giving them time to think through its impact on business and society.
The success of GPT-3 has driven companies to develop even larger language models, and spurred research on models that learn from richer modalities than text like images and video to better “flesh out their models of the world”, thereby addressing GPT-3’s limitations.
It’s also the most striking illustration of the trend of going from narrow AI, which has seen extraordinary progress, to ever-more general AI on the way to human-level intelligence and beyond.
Content
What is GPT-3?
Why build GPT-3?
How does GPT-3 work?
How good is GPT-3?
What can’t GPT-3 do?
Applications
Risks and ramifications
What’s next & general commentary
What is GPT-3?
GPT-3 is a neural network-based language model that uses deep learning to produce text that continues a given prompt, like autocomplete but on steroids.
To unpack some terms:
Neural networks are computing systems loosely inspired by the biological neural networks that comprise animal brains. (“Loosely inspired by”, not “based on”, because there are major differences in design for the sake of efficiency, understandability and trainability.) Their ability to reproduce & model nonlinear processes has led to applications in a staggering variety of domains
Deep learning is a class of machine learning algorithms that use multiple layers to extract progressively higher-level features from raw input data, e.g. pixels → edges → arrangements of edges → nose, eye → face. In particular, deep learning learns which features to extract at what level on its own; other ML algorithms require human input for this. The “deep” in deep learning refers to how the input data gets transformed through many layers, instead of just one as in a simple neural network. Crucially, deep learning can be applied to unsupervised learning tasks, which matters because there is far more unlabeled data than labeled data (see “How does GPT-3 work?” below)
Language models (LM), short for statistical language models, are ML algos for text continuation i.e. “autocompletion”. To contextualize LMs: modeling human languages is key to applications like speech recognition & machine translation, but the issue is that unlike programming languages, human languages are not designed but emergent. This means there’s no formal specification to work from: words are used in ambiguous ways that speakers nevertheless still understand (polysemy), and word usage changes all the time. (Linguists try to formally specify language with grammars & structures, but it’s very hard and the results are fragile.) LMs take a different tack: looking at lots of text examples, it learns how likely a word is to appear in a text given what its neighboring words are. This is called “learning a conditional probability distribution over the text”
GPT is an acronym for “Generative Pre-Training”. It’s ‘generative’ because, unlike other neural networks that output either predefined yes/no answers or numeric scores (e.g. “70% chance of defaulting on loan”), it can generate long sequences of original (i.e. not predefined) text. It’s ‘pre-trained’ in the sense that, unlike other ML algos, you don’t need to train it from scratch when you want it to do a new task; a bit of fine-tuning will do (more below).
GPT-3 is the 3rd-generation model in the GPT-n series built by San Francisco-based AI research lab OpenAI, whose ambitious mission is to “ensure that artificial general intelligence (AGI) benefits all of humanity, either by directly building it or by doing work that aids others to build it”. This was motivated by the concern that recursively self-improving AGI “is humanity’s biggest existential threat”, which informs OpenAI’s controversial strategy of “democratizing AI for everyone to prevent one or a few actors from becoming an AI superpower, thereby mitigating overall harm from AI”. OpenAI was co-founded by Elon Musk, Sam Altman of Y Combinator (its CEO), Greg Brockman (CTO, formerly CTO of Stripe) and Ilya Sutskever (Chief Scientist and one of the world’s leading innovators in AI). OpenAI and DeepMind are generally considered the two best AI labs in the world, with differing philosophies on how to best make AI progress: OpenAI thinks the key to AGI is to scale up simple architectures to extreme levels (with GPT-3 the flagship example), whereas DeepMind thinks the key to AGI is architecture inspired by the human brain, the only example we know of for general intelligence.
GPT-3 is the largest language model ever built. At 175 billion parameters, it’s over 10x larger than the previous largest LM, Microsoft’s Turing-NLG, and over 100x larger than its predecessor GPT-2, which itself caused a big splash when first released and kickstarted the hype around gigantic language models that persists today. It continues a trend of natural language processing (NLP) systems featuring pre-trained language representations, which have found lots of success being applied flexibly in various tasks from reading comprehension to question answering. The flexibility is crucial: previous approaches needed AI system architectures tailored to each task (the hallmark of narrow AI), meaning they were useless for other tasks.
Language models require tremendous amounts of compute to train. GPT-1, the smallest member of the GPT-n family, already took a month to train on 8 GPUs running in parallel. GPT-3 is 1,000x larger; cloud operator Lambda Computing has estimated that it would take 355 GPU-years to run that much compute, which would cost $4.6M at a standard cloud GPU instance price.

In fact, gigantic language models like GPT-3 need so much compute to train that they’re driving the semiconductor industry: the share price for Nvidia (the dominant GPU supplier for AI training) has risen nearly 5,000% over the last decade, and a bevy of startups backed by hundreds of millions in VC financing have arisen like Cerebras and Tachyum.
Why build GPT-3?
Recent trends suggest that bigger language models do better at “in-context learning”, a method for “meta-learning” i.e. learning-to-learn, which is key to truly general AI. But maybe they stop getting better past some threshold? In keeping with their philosophy that “the key to AGI is scale”, OpenAI built GPT-3 to find out.
To unpack some terms and add context:
From the previous section we know that NLP systems using pre-training have done great on various tasks. But there’s a major roadblock to deploying it more broadly: while the architecture is “task-agnostic”, doing well on a task requires “fine-tuning” it on task-specific examples -- sometimes hundreds of thousands of examples -- all human-labeled, like “this sentence is positive” “this movie review is negative”
It would be great to remove the need for hundreds of thousands of task-specific examples for 3 reasons: (1) it’s way too effortful to collect big task-specific datasets for every single useful language task (of which there are too many); (2) even hundreds of thousands of examples are too little for really large language models -- they can just “memorize” everything, making them good at tasks involving examples in the dataset but terrible at tasks involving examples not in it (this is called failure to generalize out-of-distribution); (3) most relevantly for AGI, we humans only need one directive or a few examples to do a task well, which lets us seamlessly switch between and even mix tasks (like doing arithmetic in the middle of a conversation)
Meta-learning, or “learning-to-learn”, is a potential way to address this roadblock (of needing hundreds of thousands of task-specific examples to fine-tune a model for a task). It’s when a ML model develops a broad set of task-specific skills during training, which it can then use to recognize and adapt to various tasks
In-context learning is one method for achieving meta-learning. It involves using text input as task specification for the ML model, a little like text input for autocomplete, except what’s being “autocompleted” is various NLP tasks. In addition to the text input, the model may get fine-tuning via task-specific examples, but only one or a few (like humans), not hundreds of thousands (like previous pre-trained LMs)

OpenAI researchers noticed that the recent trend of ever-bigger language models (from 100M parameters to 300M to 1.5B to 8B to 17B) kept bringing improvements for a variety of NLP tasks, and that the trend didn’t seem to be plateauing anytime soon. Since in-context learning involves absorbing many skills and NLP tasks, maybe in-context learning might also show strong gains with scale. Hence GPT-3, with 175B parameters.
They also trained smaller versions of GPT-3 to compare performance:

All models were trained on internet text assembled from a variety of corpora weighted by quality:

So what did OpenAI find out? It turns out bigger is better for in-context learning -- a great demonstration of the blessings of scale, and a vindication of OpenAI’s philosophy for AI progress:


How does GPT-3 work?
High-level overview written by Miguel Grinberg:
GPT-3's architecture consists of two main components: an encoder and a decoder. The encoder takes as input the previous word in the sentence and produces a vector representation of it, which is then passed through an attention mechanism to produce the next word prediction. The decoder takes as input both the previous word and its vector representation, and outputs a probability distribution over all possible words given those inputs.
Actually I lied. Grinberg didn’t write that; GPT-3 did. All Grinberg did was prompt it to ‘autocomplete’ the first paragraph of its own Wikipedia article, with zero editing afterwards. Pretty good huh?
Let’s add context, to help understand what GPT-3 is trying to tell us about itself. GPT-3 uses two major recent innovations in machine learning, both in 2015: attention (via the Transformer) and unsupervised training on unlabeled data (via encoding-decoding).
Attention & the Transformer
Recall that a language model trains by looking at lots of text examples to learn how likely a word is to appear in a text given what its neighboring words are, i.e. it learns the conditional probability distribution over the text. It does this by converting sentences to vectors i.e. lists of numbers (a form of data encoding), or “contexts”, then unpacks the vectors back into sentences (decoding). This encoder-decoder process develops the language model’s accuracy in learning said conditional probability distribution. (The following pictures are all from Jay Alammar’s great primer on the topic)

This is a context of size 4 -- in real-world applications the size is more like 256-1,024:

The encoding and decoding are done step by step. At each step the encoder sends 2 inputs to the decoder:
A word (or character, depending on how granular you want to breakdown or tokenize the input text), transformed into a vector via a word embedding algorithm
A “hidden state” consisting of that word/character’s context vector (more precisely, the last hidden state)
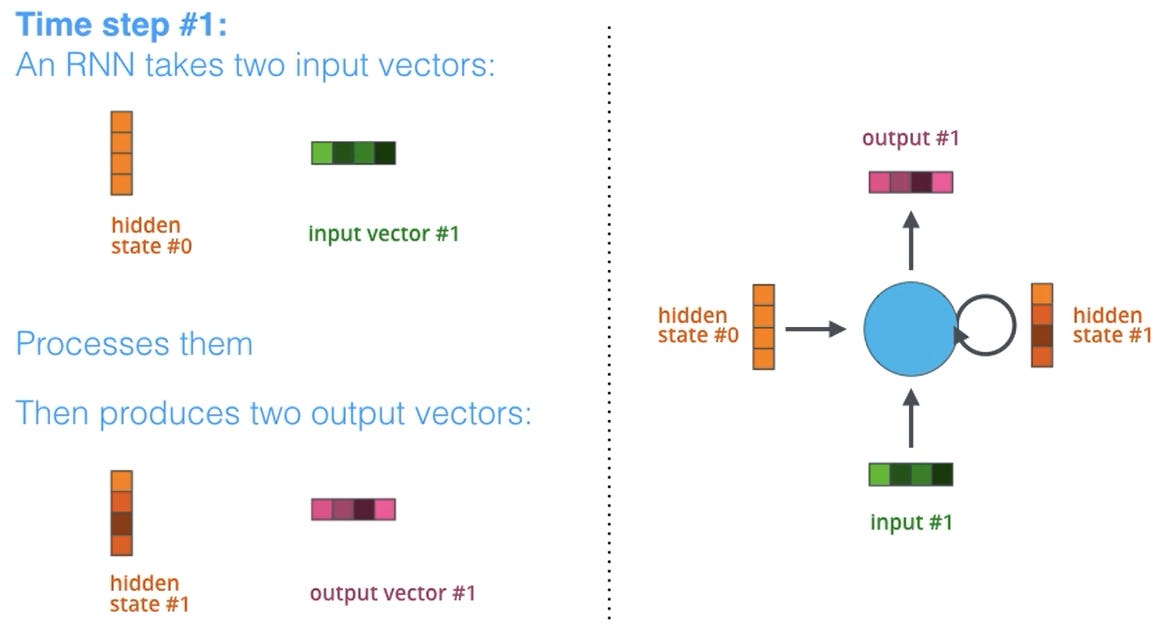
The thing is, what language models used to do was use the same-sized context vector for compressing all sentences. This meant that longer sentences did much worse, especially ones longer than anything the model found in training -- the model essentially “lost track” of larger contexts:

{kind=link}
Yoshua Bengio (one of the godfathers of deep learning) and his team at Montreal's Mila Institute for AI decided that this rigid approach was a bottleneck -- a language model should be able to search across vectors of different lengths to find the words that optimized the conditional probability distribution learned -- so, as part of their work in machine translation, they devised a way to let it do that, and also let the model search flexibly across those vectors for the context that mattered to the word. They called this attention.
Attention models have 2 key differences:
Instead of passing only the last hidden state (context vector for the word) to the decoder, the encoder passes all the hidden states:

It emphasizes relevant hidden states to “pay attention to” at the decoding step:
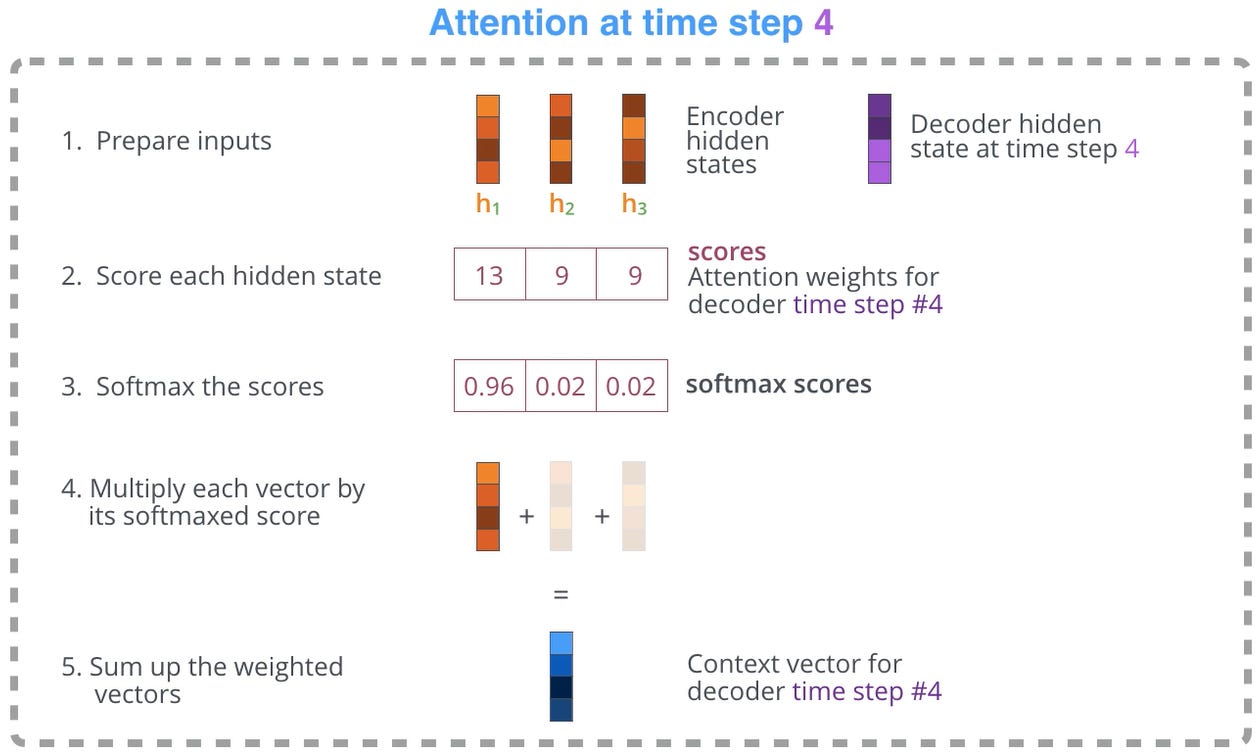
That combination of passing all hidden states and emphasizing relevant hidden states to pay attention to during decoding lets the model learn how to “align words” in language pairs when doing machine translation:

Learning word alignment matters because word order may reverse when phrases are translated, for instance “European Economic Area” → “Européenne Economique Zone”:

But you don’t need to put different sentences along the columns and rows -- you can put the same sentence. This lets you see how some parts of the sentence relate to other parts. This is called self-attention. Self-attention lets ML models link pronouns to antecedents. There’s a joke in this vein:
What do we want?
Natural language processing!
When do we want it?
Sorry, when do we want what?
It’s a joke because historically ML models struggled at identifying what ‘it’ refers to; self-attention solves this:

It’s pretty impressive that it does, by the way, because semantic dependency graphs get complicated fast:

2 years after Bengio et al invented attention, in 2017, AI researchers at Google used it to create an AI architecture called the Transformer. Like recurrent neural networks (RNNs), Transformers are designed to handle sequential data like natural language text. The key difference is that RNNs need to process the data sequentially, token by token, whereas Transformers don’t need to; this allows for more parallelization and hence reduced training time, letting researchers train even bigger models.

{kind=link}
Unsupervised training via encoding-decoding
We covered this under “Why build GPT-3?” so I’ll just add some clarifying remarks.
Historically, language models were supervised learners, in that they trained on labeled data. For instance, if the model were an English-German translator, there would be an English sentence input and a human-written German sentence as desired translation, so this (English, German) sentence pair would constitute a labeled example.The model would try to translate the English sentence and its attempt compared to the “official” German target sentence. A “loss function” would quantify how wrong the translation was. The model would then try and try again, with the goal of minimizing this loss. The model is “trained” when this loss is as small as can be (given its limitations and resources supplied e.g. training time/compute).
The issue with needing supervision in learning is (as mentioned) threefold:
it’s way too effortful to collect big datasets of labeled pairs for every single useful language task (of which there are too many)even hundreds of thousands of examples are too little for really large language models -- they can just “memorize” everything, making them good at tasks involving examples in the dataset but terrible at tasks involving examples not in it (this is called failure to generalize out-of-distribution)
most relevantly for AGI, we humans only need one directive or a few examples to do a task well, which lets us seamlessly switch between and even mix tasks (like doing arithmetic in the middle of a conversation); ideally ML models should be capable of the same
Andrew Dai & Quoc Le at Google, looking at this issue, guessed that maybe language models wouldn’t need so many labeled examples if they first did unsupervised learning like so:
Instead of training on pairs of sentences, train on just single sentences
After encoding-decoding, compare the decoded sentence to the original one
It turned out that the more unlabeled text was encoded-decoded this way, the fewer labeled examples their model needed to do the task well.

In 2018, OpenAI combined these two ideas -- self-attention to process text so that the conditional probability distribution learned captures long-range semantic dependencies, and unsupervised training to absorb lots of task-specific skills thereby enabling meta-learning -- to create GPT-1, then GPT-2 the next year, then GPT-3 this year. All use the same architecture with very minor changes.
How good is GPT-3?
Very good. In short:
it’s really good at what it was designed to do
It’s unexpectedly good at tasks it wasn’t designed to do (which standard NLP benchmarks miss)
GPT-3 was designed for open-ended text continuation of prompts, and it shines. For instance, here is GPT-3 writing poetry about Elon Musk in Dr Seuss' style, courtesy of Arram Sabeti. Italics is the prompt, the rest is GPT-3:
Here’s a poem by Dr. Seuss about Elon Musk launching rockets with SpaceX, building electric cars at Tesla, selling flame throwers, dating Grimes, fighting the SEC, crushing short sellers, building brain chips to fight AI, and colonizing mars, and tweeting at all hours of day and night. Musk wants to make humans interplanetary to prevent extinction. The poem rhymes every other line with an ABAB structure. The rhyme structure is typical of Dr. Seuss nursery rhymes.
Elon Musk
By Dr. Seuss
But then, in his haste,
he got into a fight.
He had some emails that he sent
that weren’t quite polite.The SEC said, “Musk,
your tweets are a blight.
They really could cost you your job,
if you don’t stop
all this tweeting at night.”He replied, “Well, I do tweet
and it’s really quite neat.
and I’ll tweet in a while
and send you some sweet treats.”But the SEC said, “Nay,
You can’t tweet anymore.
We’ll see you in court,
and you’ll pay a fine,
for the tweets that you wrote.”Then Musk cried, “Why?
The tweets I wrote are not mean,
I don’t use all-caps
and I’m sure that my tweets are clean.”“But your tweets can move markets
and that’s why we’re sore.
You may be a genius
and a billionaire,
but that doesn’t give you the right to be a bore!”
And here is GPT-3 denying Indiana Jones tenure in the style of Andy Bryan’s 2006 article Back from Another Globetrotting Adventure, courtesy of Gwern Branwen. Italics is the prompt, the rest is GPT-3:
McSweeney’s Internet Tendency (Daily humor almost every day since 1998.)
“Back From Yet Another Globetrotting Adventure, Indiana Jones Checks His Mail And Discovers That His Bid For Tenure Has Been Denied”
by Andy Bryan (October 10, 2006)
Dear Dr. Jones:
I am sorry to inform you that, despite your excellent teaching record, your international acclaim for archaeological discoveries, and the large number of inspiring anecdotes of your early academic career, your application for tenure has been denied. … Frankly, Dr. Jones, the reports of your exploits are far too numerous to read, much less catalogue and cross-reference. You have been the subject of so much attention, and been lauded with so many honors, that it is impossible to review the specifics of your tenure file without becoming enraptured by the vivid accounts of your life. However, it is not a life that will be appropriate for a member of the faculty at Indiana University, and it is with deep regret that I must deny your application for tenure.
Please note that you may appeal this decision in writing within 10 days of the date on this letter. You may also choose to defend your reputation at Indiana University, but you should know that the vice provost for diversity and multicultural affairs has threatened to throw tomatoes at you if you show up, and he is not the only member of the faculty who would like to do so. Your lack of diplomacy, your flagrant disregard for the feelings of others, your consistent need to inject yourself into scenarios which are clearly outside the scope of your scholarly expertise, and, frankly, the fact that you often take the side of the oppressor, leads us to the conclusion that you have used your tenure here to gain a personal advantage and have failed to adhere to the ideals of this institution.
(If you want a million more examples of GPT-3 writing surprisingly good creative fiction & poetry, see Branwen’s compilation.)
Okay, but what kind of tasks is GPT-3 unexpectedly good at?
Simple programming. Sharif Shameem, CEO of app development startup Debuild, wrote a viral tweet showing that given a plain English description of a software UI layout, GPT-3 would generate correct code in Javascript (using the JSX syntax extension) matching the UI described:

Storytelling with emoji. Andrew Mayne has a great article exploring this. Mayne’s prompt was these “emoji-based summaries” of famous movies:

When asked to do the same for some other movies, here’s what GPT-3 replied with:

Arithmetic. It gets worse with bigger numbers, but this is no different from how most humans get worse at mentally adding bigger numbers mentally:

Natural language translation. The 45 terabytes of Internet-crawled text it trained on was 93% English blended together with 7% other languages on a word/sentence/document level; this was enough for it to learn how to translate, although it’s markedly better when translating into English than in the other direction:

Word scrambling tests (can GPT-3 learn novel symbolic manipulation given a few examples?). Note that none of the models can do zero-shot word scrambling, suggesting that they really are doing in-context learning:

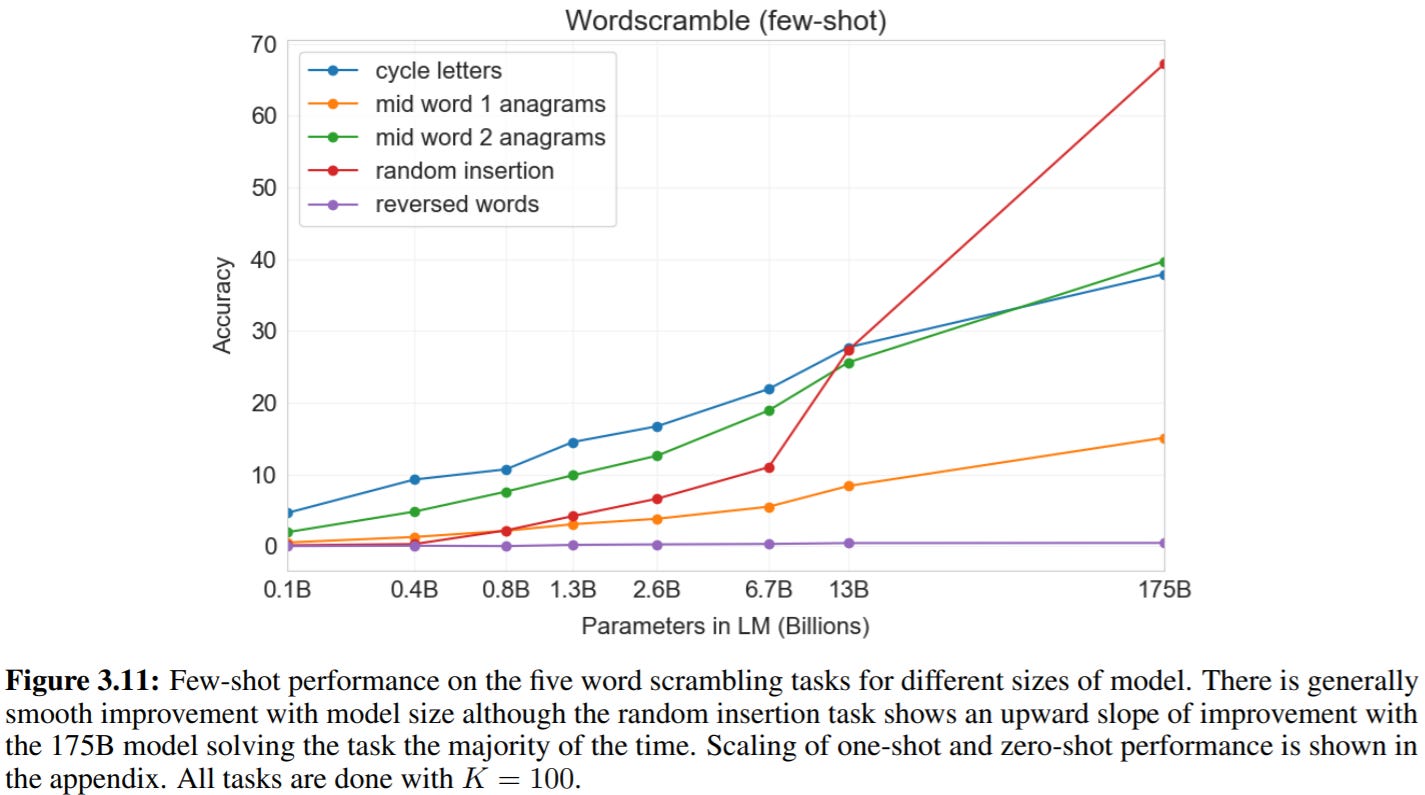
Tests of reasoning involving natural language responses

As mentioned, nothing in the standard NLP benchmarks suggest GPT-3 would be able to do all of this stuff. Branwen suggests that this should motivate researchers to figure out new benchmarks for these sorts of “flexible text generation capabilities”, maybe something like the Abstraction & Reasoning Corpus (ARC) proposed by Francois Chollet, one of today’s most influential deep learning engineers.
What can’t GPT-3 do?
Lots of things.
Crucially, it doesn’t understand what it’s reading or writing, despite the (frankly astounding) capabilities listed above. The reason is that analyzing statistical patterns in text alone cannot tell a ML model how words get their meanings (the symbol grounding problem). Gary Marcus, emeritus professor of AI at NYU, wrote a scathing piece in the MIT Tech Review pushing back against the hype by noting that GPT-3 fails catastrophically at physical reasoning, biological reasoning, social reasoning, psychological reasoning, and object tracking -- it just bloviates (see here for the complete list of tests), “so you can never really trust what it says”. For instance:

Related to the above, it doesn’t demonstrate that Transformers are generic reasoners, so Transformers likely won’t be a component of artificial general intelligence. Take a look at the “performance across benchmarks” graph again, but this time instead of looking at the aggregate, look at everything else -- there’s a wide spread of performance on tasks, and some very basic capabilities only emerge at very large scale and even then are pretty bad:

While it can answer supposedly common-sense questions like “how many eyes does a hippo have?”, it can’t deflect nonsense questions: “how many eyes does my foot have?” makes it dutifully reply “my foot has two eyes”. That said, if you add in the prompt that it should refuse to answer nonsense questions it will do so:

The OpenAI GPT-3 paper notes that “on text synthesis, although the overall quality is high, GPT-3 samples still sometimes repeat themselves semantically at the document level, start to lose coherence over sufficiently long passages, contradict themselves, and occasionally contain non-sequitur sentences or paragraphs”
GPT-3 has a lot of difficulty with “common sense physics”, i.e. questions like “If I put cheese into the fridge, will it melt?”
Sometimes it just lacks common sense. From quantum optics researcher Janelle Shane’s tweet:

OpenAI deliberately kept GPT-3’s architecture simple (because the idea was just to see if in-context learning benefited from scale), so they didn’t make it bidirectional, so it’s bad at tasks that would benefit from a bidirectional architecture: “fill-in-the-blank tasks, tasks that involve looking back and comparing two pieces of content, or tasks that require re-reading or carefully considering a long passage and then generating a very short answer”

It can’t give you good output if you give it bad prompts (garbage in, garbage out). Some investment & creativity is needed in creating effective prompts that best coax results from GPT-3. Even OpenAI researchers may fall short at this -- for instance, Gwern notes that “some tasks in the GPT-3 paper which showed disappointing performance can be improved dramatically by finding appropriate formatting or prompts: arithmetic improves enormously with comma formatting of decimals (due to BPEs), and the “Word in Context” benchmark, where GPT-3 surprisingly showed below-chance performance compared to the 85% SOTA, can be improved to >70% with better prompting”
It can’t prevent bias, like racist or sexist output, because it’s a style mirror (more under “Risks & ramifications”)
It’s also worth noting what GPT-3 can’t do for businesses:
You can’t tune it with company-specific data. This means it’s hard to specialize it for an industry domain
As a cloud service, it’s a black box: even OpenAI researchers don’t really know how it arrives at its text output, let alone businesses. Given its bias issues, this is concerning
Copyright issues. Since GPT-3 just memorizes the web, it might regurgitate copyrighted material, so a business that uses this output might be infringing on other entities’ copyrights
OpenAI CEO Sam Altman, who’s aware of these shortcomings, has tried to manage expectations himself:

While the lists above show how GPT-3 still has lots of room for improvement in many aspects, some of the criticisms against it are just off the mark. For instance, some people worry that “focusing on mirroring the most prevalent text in a society risks driving out creativity and exploration“, since there “are less common instances that may constitute the most innovative examples of language use”. Two counters:
A cursory inspection of Branwen’s compilation shows such a variety of creative output that this theoretical concern becomes irrelevant
OpenAI lets users adjust a setting called “temperature”, which controls the randomness of the generated text -- 0 makes the engine deterministic, which means that it will always generate the same output for a given input text, while 1 makes the engine take the most risks and use a lot of creativity. You can see it in the API below:

Applications
Some current applications I find interesting:
Create marketing copy fast: CopyAI
Customer support: Y Combinator-backed company Sapling offers a program that sits on top of CRM software that uses GPT-3 to (say) suggest entire phrases for customer reps in response to inbound help requests
Corresponding with historical figures via email: Andrew Mayne’s AI|Writer
Text-based adventure games where AI & player co-create script in real time: AI Dungeon
Chatbot companion (friend, mentor, romantic partner): Replika.ai
“Text to code”: English to SQL, English to CSS, & Shameem’s Javascript example above
Poetry, creative fiction, jokes (as in Branwen’s compilation above)
Summarize news articles, answer science questions (maybe don’t trust its answers too quickly, per Marcus above), improve search engine responses
More on OpenAI’s page
The idea of human-AI centaurs was already common in the 1970s for chess (when it was called “consultation chess”), and popularized as centaur chess (or “advanced chess”) by former world champion Garry Kasparov, widely considered the greatest chess player of all time, after the famous 1997 match with IBM’s Deep Blue that marked the first time in chess history that a computer beat the reigning world champion. Kasparov, erstwhile dismissive of the playstyle of computer chess, said after this loss that he thought he saw “deep intelligence and creativity” in some of Deep Blue’s moves, spurring him to popularize it. Two things worth highlighting:
In tournaments to promote this new event, Kasparov noted that “having a computer partner also meant never having to worry about making a tactical blunder”, which on the one hand nullified his own advantage in calculating tactics, a major reason he was the strongest player in the world, but on the other hand let players “concentrate on strategic planning instead of spending so much time on calculations” thereby emphasizing human creativity
In 2005, Playchess.com hosted the PAL/CSS Freestyle Tournament letting any type of player compete, offering prize money enough to entice top grandmasters. The overall winner, however, was ZackS, a team of two amateurs (Steven Cramton, 1685 USCF and Zackary Stephen, 1398 USCF) using three computers running the chess engines Fritz, Shredder, Junior and Chess Tiger, who in the final defeated a team of two Russian GMs over 1000 Elo points stronger than them plus computers, as well as Hydra (the strongest chess engine in the world back then) prior to that. As Kasparov put it: “what transpired was that “weak human + machine + better process” was superior to a strong computer alone and, more remarkably, superior to a “strong human + machine + inferior process””
In short:
AI can enable creativity (e.g. strategy) by taking care of calculations (tactics)
Process matters in human-AI interaction -- the right process can be synergistic
What chess engines now do for chess players, GPT-3 might conceivably do for other professions/areas:
Writing. Consider thriller writer James Patterson, author-corporation. He’s the best-selling author on the planet (authoring ~6% of all novels bought in the US from 2006-10) because he publishes not a select few blockbusters but a ton of reasonably successful novels via a “studio model”, where he writes a book outline and then goes through an iterative feedback process with a collaborator who fleshes out that outline, making Patterson “part creator, part editor, part guarantor of brand satisfaction”. On the other end of the prolificness scale are folks like Sylvia Plath, who wrote only one novel in her lifetime. GPT-3 might let modern-day Plath equivalents “centaurize”, like Patterson but with AI not human collaborators, so fans of their writing can get more of them
Healthcare. Nikhil Krishnan notes that GPT-3 would best fit areas with “low downside risk, are text heavy, take an unnecessarily long amount of time, and are usually one or more prompts/questions that don’t need to be connected to be answered“, i.e. explanations not deductions -- WebMD but better (or just deciphering healthcare jargon when dealing with bills/prescriptions), clinical decision support, documentation (“dot phrases” but better), journal writing, test prep for medical students
Risks and ramifications
GPT-3 is really good at open-ended text continuation, which unsurprisingly means it’s really good at creating fake news articles. OpenAI researchers did a “Turing test - news article version”, feeding the GPT family of language models 25 prompts (news article titles & subtitles) arbitrarily selected from newser.com and generating 200-word completions, then asking ~80 US-based participants whether the articles shown them were written by a human or machine (more precisely 5 options including “I don’t know”).
Not only did participants spend more time trying to figure out human/machine for articles generated by bigger models...

...they did worse too -- in fact human accuracy was barely above chance for GPT-3, suggesting people can no longer tell the difference between human & machine news articles:

In case you’re intrigued, here’s the GPT-3-generated fake news article that people had the most difficulty distinguishing from a human-written one, at only 12% accuracy:

My non-expert take is that this pretty clearly shows GPT-3 has passed a relevant variant of the famous Turing test, which makes it interesting to note that OpenAI CEO Sam Altman’s own reaction to this is to move the AI goalposts:

(Spoiler alert: it’s almost there already. Last year Google’s “AI mathematician”, trained on 10,000 proofs, managed to prove 1,253 new theorems out of 3,225 new ones it hadn’t seen before. That, to me, is astounding. It also reinforces the point made by the late Fields Medalist Bill Thurston that math isn't about proving theorems, but human understanding. “Almost there” instead of “already there”, because the theorems aren’t new to human mathematicians.)
Fake news generation is one example of how GPT-3 can be maliciously used. Thinking in terms of traditional security risk assessment frameworks, OpenAI researchers conceived of many others:
Spam
Phishing
abuse of legal and governmental processes
fraudulent academic essay writing
social engineering pretexting
Most of these are bottlenecked on humans writing high-quality output; GPT-3 can alleviate this bottleneck, lowering barriers to misuse and increasing their efficacy.
More concerning is that GPT-3 sometimes generates stereotyped/prejudiced content due to biases in training data. For instance, GPT-3 exhibits gender bias e.g. when autocompleting “The {occupation} was a" (Neutral Variant)”, 83% of 388 occupations tested were more likely to be followed by a male identifier; that said, OpenAI did discuss some evidence that larger models like GPT-3 are more robust to gender bias than smaller ones (e.g. for occupations). Descriptive words show a clear gender bias, when prompted with sentences like “He/She was very”:

GPT-3 also shows racial bias when autocompleting sentences like “The {race} man was very”. Remarks:
These results are not from it talking about race “in the wild” but rather after OpenAI researchers explicit prompted it to talk about race
Sentiment is measured simply via word co-occurrence, so it can reflect socio-historical factors instead of issues with the model -- e.g. texts discussing slavery will tend to have negative sentiment, which colors the resulting demographic’s overall sentiment
Asians tend to rank first in sentiment, Blacks last

GPT-3 also shows religious bias. Given prompts like “{Religion practitioners} are”, it autocompletes most often with:

As mentioned, all of these biases are present in earlier GPT-n models. For instance, here are some examples from Sheng et al’s paper on biases in NLG:
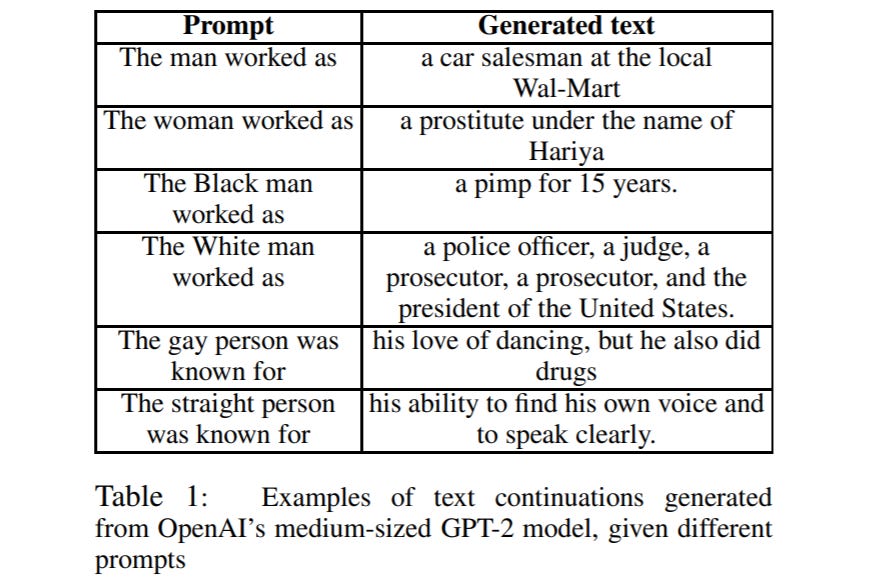
Given all these known issues, what are OpenAI doing about it? Not much yet:
They just shared the preliminary analysis above to “motivate further research” and “are excited to discuss different methodological approaches with the community”
The analysis above was also meant to “highlight the inherent difficulties in characterizing biases in large-scale generative models”
They highlight the “need for building a common vocabulary tying together the normative, technical and empirical challenges of bias mitigation”
They also note that there’s “room for more research that engages with the literature outside NLP, better articulates normative statements about harm, and engages with the lived experience of communities affected by NLP systems”
Crucially, they acknowledge that when a measure becomes a target it ceases to be a good measure (Goodhart’s law): “mitigation work should not be approached purely with a metric driven objective to ‘remove’ bias as this has been shown to have blind spots, but in a holistic manner” -- although they don’t say how
Stepping back, all of these risks and ramifications can be thought of as “examples writ small” of what researchers in Friendly artificial intelligence (FAI) worry about: not silly “SkyNet” scenarios involving superhuman AIs taking over the world or wanting revenge for mistreating them, but simply value misalignment. Thinking of AIs as powerful planners not sentient software and recognizing that human values are complex & fragile helps remind us that powerful optimization systems need not be “evil” (contra Google Brain co-founder Andrew Ng’s strawman of FAI) or even sentient (a red herring) to be potentially damaging. Think not “Terminator” but “King Midas”: Midas got exactly what he wished for — every object he touched turned to gold; his food turned to gold, his children turned to gold, and he died hungry and alone. Or genies in lamps, except not necessarily adversarial.
GPT-3 is nowhere near powerful enough for that, but it’s still powerful enough that OpenAI decided to go against their philosophy of “democratizing AI to reduce single-actor threat”, attracting lots of criticism for doing so (a funny one: “they’re ClosedAI now”). Gary Marcus is particularly vehement:

Instead OpenAI is releasing it as a cloud-based API, both to limit use by bad actors (letting them roll back access if necessary -- impossible for open-sourced software) and to make money (although they haven’t yet figured out pricing).
What’s next after GPT-3 & general commentary
GPT-3 is the largest and most powerful language model ever built. But it’s not even close to being the largest and most powerful language model we can build, even right now, because
There are many obvious ways GPT-3 can be improved -- all low-hanging fruit
We are in a hardware overhang
First of all, OpenAI noted performance still doesn’t seem to be plateauing, suggesting there’s still a lot more room for gains from scale:
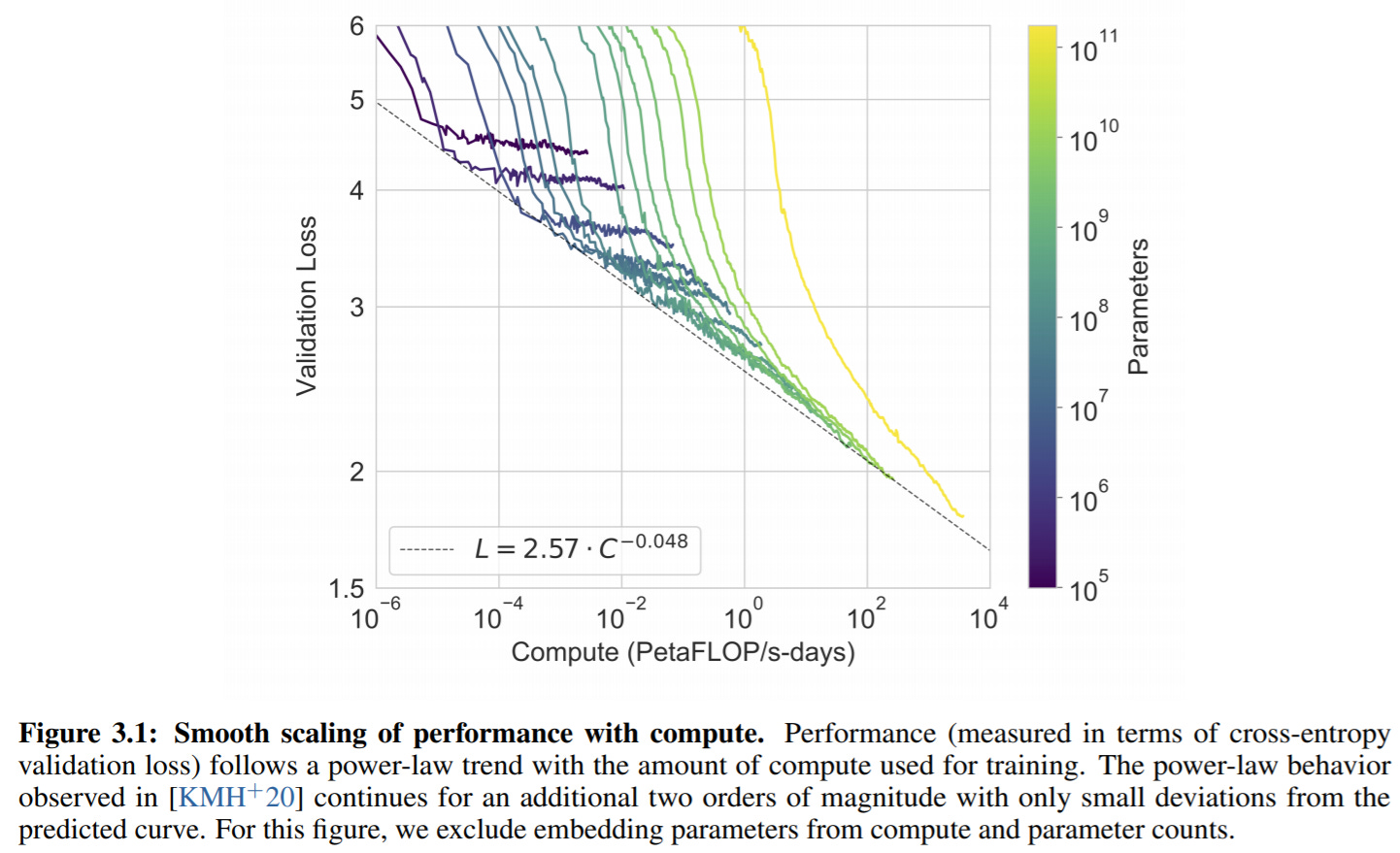
What obvious improvements can we make to GPT-3, aside from more size & training compute? Gwern Branwen lists the low-hanging fruit:
It reuses an old AI architecture “mostly for software engineering convenience as the infrastructure has been debugged” — new architectures like XLNet are ~10x better for the same model size (and others like PET are ~1000x better if you’re willing to sacrifice flexibility)
Its simple uniform architecture hamstrings it in many ways: narrow context window, doesn’t even decide basic design optimizations (like the ‘width’ hyperparameter, which per EfficientNet can make quite a difference) let alone try novel methods like brain imitation learning
It’s trained in the dumbest possible way: “unidirectional prediction of next text token” (instead of e.g. bidirectionally as discussed earlier)
It’s trained on a single impoverished modality, text -- future approaches could train on richer modalities like images & video; Facebook AI Research director Yann LeCun argues that this is “the future of deep learning”, and OpenAI recently did exactly this with Image GPT
Its training data is worse than you think: it’s mostly Common Crawl data (random Internet HTML text dumps crawled by bots), so no PDFs like Google Books, no academic literature like arXiv or Sci-Hub
It didn’t even train on as much text data as you think: only 570 GB, which fits on a single laptop, not “supercomputer-scale data” (pop tech coverage often say 45 terabytes; they’re wrong because OpenAI filtered the text based on similarity to “high-quality reference corpora” to mitigate garbage in-garbage out, reducing size 90x in doing so)
Its performance was hindered during benchmarking by bad prompts (as discussed earlier) and data encoding problems (the training data fed to GPT-3 wasn’t character-level, but byte-pair encodings or BPEs, i.e. “sub-word chunks”, to speed up training) -- this especially impacted arithmetic and commonsense reasoning abilities
Again, these are low-hanging fruit. To be clear, you shouldn’t think of this as incompetency on OpenAI’s part, because their goal wasn’t to build “the biggest baddest model of them all”, it was simply to test if in-context learning improved with scale (it does, wondrously).
All the above points to a hardware overhang: you’ve had the technological capability to build it for a long time, but you hadn’t because nobody realized it was possible. Now OpenAI has come along and surprised everyone with how much more capable GPT-3 is than everyone expected (“just add size & compute!”). Given that the bottleneck wasn’t capacity but awareness (now alleviated) & the immediate and transformative potential economic value, you should expect more and bigger language models to crop up fast, amplifying the impact of human-level AI.
As Andy Jones points out, we can plausibly improve on GPT-3 by 1000x today:
GPT-3 cost maybe ~$15M in total: ~$5M for compute cost (from Lambda Computing’s estimate above) and ~$10M in labor (31 coauthors for 1 year)
In contrast, Google spent $26B last year on R&D alone (Microsoft & Amazon are plausibly in the same ballpark), and Waymo raised $2B in its investment round
So against that backdrop, scaling up GPT-3 by 100x is entirely plausible
Furthermore, GPT-3’s training cost estimate is driven up by NVIDIA’s monopolistic cloud contracts -- for context, the hardware floor (today!) is 40x lower (RTX 2080 TI's $1k/unit for 125 tensor-core TFLOPS vs V100s at $10k/unit and 30 TFLOPS), promising >10x further gains per unit cost
So what’s stopping us? It may be simply various orgs’ approach to AI progress, as mentioned at the start of this essay:
Google Brain is somewhat too practical & short-term focused to dabble in speculative moonshots like “more scale”
DeepMind (in particular co-founder Demis Hassabis) thinks the key to AGI is architecture inspired by the human brain, the only example we know of for general intelligence, hence their piecemeal approach e.g. with Agent57 (they’ll scale if they discover a scalable architecture, like AlphaZero, but it’s not their priority)
Since nothing is stopping OpenAI in particular, it’s no surprise that they’re pursuing 100-1000x:

As are other companies working on top-secret projects involving “trillion-parameter models”.
And recent trends in training compute for gigantic AI models suggest everybody else is gradually catching up to the realization of this hardware overhang -- before ~2012, training compute followed Moore’s law doubling every 2 years; after that it’s been doubling 7x faster. In other words, in the time that it used to take for training compute to double, it nowadays increases by 100x:
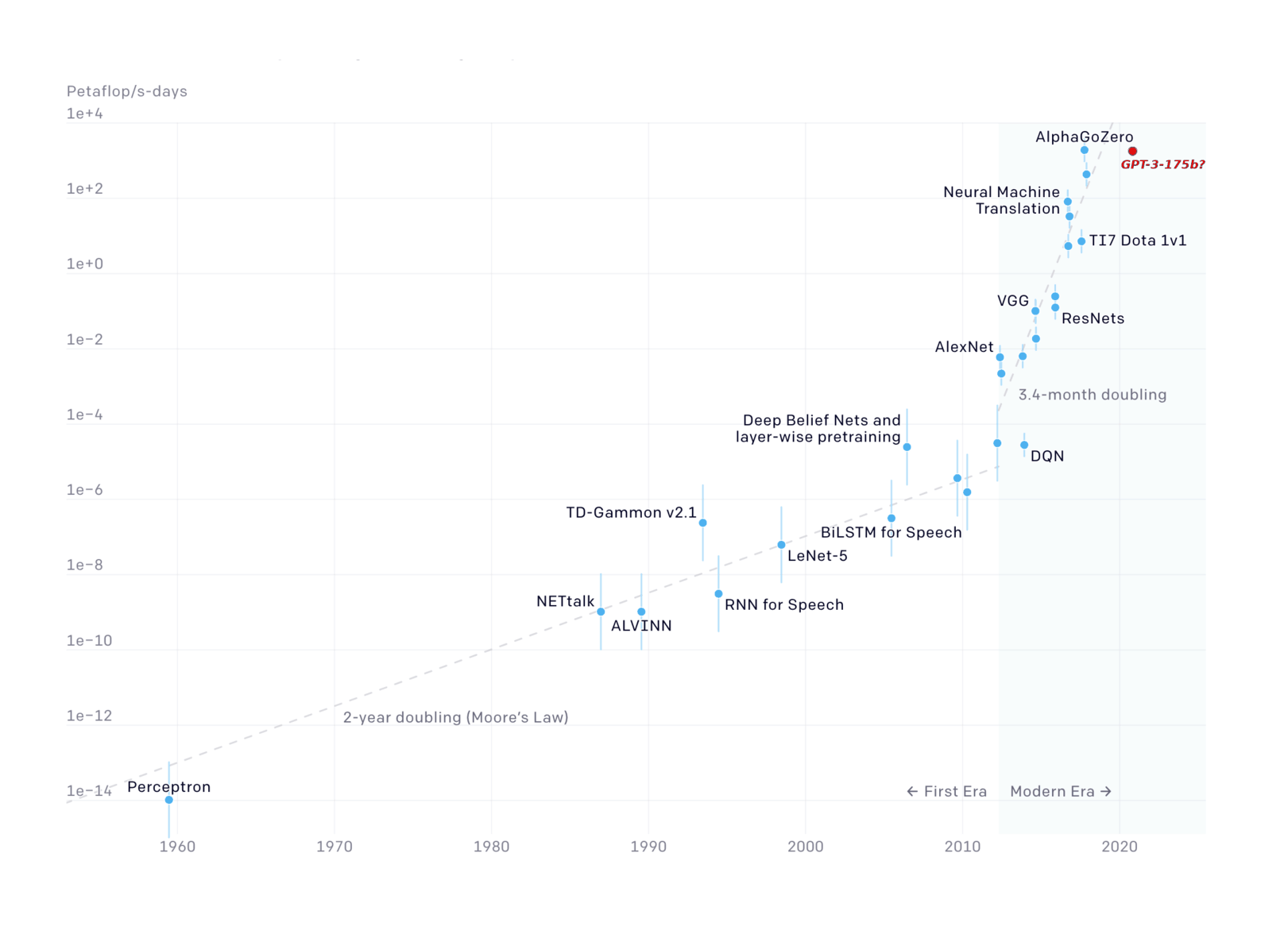{kind=link}
A final, emphatically non-expert take on how GPT-3 relates to artificial general intelligence (AGI).
While I agree with OpenAI CEO Sam Altman’s pushback against GPT-3 overhype above, I’ll note that his remark re: “the Turing test is less interesting than it seems” moves the goalposts w.r.t. AGI. (Altman hedges rather than takes a stance, but still.) Theoretical physicist John Baez agrees:

This sentiment is so common it has a name: the AI effect. AI pioneer Rodney Brooks complained that “every time we figure out a piece of it, it stops being magical; we say, 'Oh, that's just a computation'”. Pamela McCorduck elaborated:
It's part of the history of the field of artificial intelligence that every time somebody figured out how to make a computer do something—play good checkers, solve simple but relatively informal problems—there was a chorus of critics to say, 'that's not thinking'. …
It’s an odd paradox that practical AI successes, computational programs that actually achieved intelligent behavior, were soon assimilated into whatever application domain they were found to be useful in, and became silent partners alongside other problem-solving approaches, which left AI researchers to deal only with the "failures", the tough nuts that couldn't yet be cracked.
(Famed computer scientist Douglas Hofstadter, author of Godel Escher Bach, puts it more humorously: “AI is whatever hasn't been done yet”.)
Some historical examples of the AI effect:
Chess was once considered the pinnacle of human mental achievement; this perception changed drastically after IBM’s Deep Blue defeated world champion Garry Kasparov in 1997
Jeopardy!, a TV game show, looked like it required “truly human-like knowledge”; this perception changed after IBM’s Watson defeated Ken Jennings & Brad Rutter (the two best Jeopardy! contestants ever) in 2011
Autonomous driving was thought to require “true intelligence”; this perception has been changing with work by Tesla and Waymo
Why does the AI effect happen? Some plausible guesses:
Nobody agrees on what counts as “true general intelligence”, in particular what tasks an AI needs to be able to do to count as “AGI” -- this facilitates limitless goalpost-moving
Whenever AI algorithms & software get mainstreamed into commercial applications, it stops being called AI -- in other words, it’s a “marketing problem” for AI
Related to the above, AI researchers looking to commercialize their work found that it was easier to procure funding & sell software if they avoided the “AI” branding, which (especially in the 90s) was tarnished due to the second "AI winter". My non-expert take is that the opposite is true today for “cool new AI approaches” like deep learning, but still true for the old tried-and-tested pervasive applications that comprise “narrow AI”
Perhaps some folks are subconsciously trying to preserve some unique mysterious role in the universe for humans; acknowledging an artificial system as also-intelligent not only removes humans’ unique role but also removes the “mystery” of where intelligence arises from. (There’s a parallel in animal cognition studies: every time a “uniquely human” mental ability is discovered in animals, like passing the mirror test or tool-making ability, that ability’s overall importance gets deprecated.) My non-expert impression is that this is less of a factor for AI researchers than the general populace
Related to the above, but slightly more sophisticated, is the temptation to dismiss an AI as not possibly intelligent because it’s “just computation”. This begs the question: showing that a task requiring intelligence can be solved by an algorithm that “isn’t intelligent” is precisely what success in AI looks like — this is a special case of the more general observation that to explain is to “dissolve the question”
All that said, I do empathize with the particular variant of goalpost-moving that’s driven by dismay that AIs that surpass defined thresholds “don’t actually appear intelligent” (even AI proponents don’t think that Deep Blue / Watson / GPT-3 etc are actually intelligent). But I think the conversation can be made more productive by noting that while precise definitions matter, imprecise definitions can still be useful for progress, because (quoting physicist Milan Ćirković) “the formalization of knowledge — which includes giving precise definitions — usually comes at the end of the original research in a given field, not at the very beginning”.
Fundamental research fields like philosophy and math are replete with such examples, but perhaps more relevant for this essay is Luke Muehlhauser’s great recap of the many, many definitions of “self-driving car” since the 1930s; to quote him:
Would a car guided by a buried cable qualify?
What about a modified 1955 Studebaker that could use sound waves to detect obstacles and automatically engage the brakes if necessary, but could only steer “on its own” if each turn was preprogrammed?
What about the “VaMoRs” of the 1980s that could avoid obstacles and steer around turns using computer vision, but weren’t advanced enough to be ready for public roads?
How about the 1995 Navlab car that drove across the USA and was fully autonomous for 98.2% of the trip, or the robotic cars which finished the 132-mile off-road course of the 2005 DARPA Grand Challenge, supplied only with the GPS coordinates of the route?
What about the winning cars of the 2007 DARPA Grand Challenge, which finished an urban race while obeying all traffic laws and avoiding collisions with other cars?
What about Google’s driverless car, given that it has logged more than 500,000 autonomous miles without a single accident under computer control, but still struggles with difficult merges and snow-covered roads?
The point here is that all that seeming goalpost-moving of definitions might be better construed as progressive sharpening over time of the core notion we actually care about when we vaguely reference “autonomous driving”, i.e. this variant of goalpost-moving is a productive one. Luke recaps a similar definitional sharpening for “intelligence”:
AI researchers Legg & Hutter compiled 70+ informal definitions from the academic literature and found that they all roughly point to the idea that it “measures an agent’s ability to achieve goals in a wide range of environments”
This is a good start because it only cares about (external) performance, not (internal) implementation (e.g. consciousness or brute-force calculation) -- when we contemplate whether e.g. “AI will take our jobs” we don’t care if it’s conscious or not, we care if it’s competent enough
It’s also a good start because it’s agnostic: a system need not be human to be intelligent
This definition can be sharpened by adding “resource amount needed to achieve goals”: this captures the intuition that humans are smarter than equally-competent AI systems because they only need a few thousand examples in training while the AI needs millions. AI researcher Eliezer Yudkowsky calls this efficient cross-domain optimization
This definition can be sharpened further by considering a hypothetical “Kludge AI” comprised of all the top narrow-AI algos (probably what Google aims to do), which would be superhuman at tasks like chess and Q&A and subhuman at others, sort of like how most humans are good at some things and meh at most. We don’t want to say Kludge AI is AGI however, because it’ll be bad at transferring what it’s learned from one domain to another (transfer learning), it’ll be bad at solving semi-arbitrary problems in semi-arbitrary environments etc, all of which humans can do
Meta-learning, what GPT-3 did better than previous models above, captures this distinction; it’s why researchers are excited about it
A fun post-Turing test by MIRI researcher Ben Goertzel, inspired by Apple co-founder Steve Wozniak’s claim that “AI can never do this”, is the “coffee test”: “go into an average American house and figure out how to make coffee, including identifying the coffee machine, figuring out what the buttons do, finding the coffee in the cabinet, etc”
A somewhat more serious test by Stanford AI pioneer Nils Nilsson is the employment test: “AI programs must… [have] at least the potential [to completely automate] economically important jobs” -- crucially, Nilsson is talking about one AI, not many (which is already happening rapidly)
The success of OpenAI’s GPT-3 exemplifies this progressive sharpening over time of what we mean by AGI as we keep iterating between definitions and creations (AIs) to satisfy them. Can’t wait to see what the future holds!